
Unlock the Power of Model Fusion in Railway Environments – A Case Study on Catenary Pole Detection
- Data Science - R&D
- Feb 13, 2024
- 7 min read

Context
Electric trains -the backbone of modern eco-friendly, and safest means of transportation- rely on a sophisticated network of catenary poles to support overhead power lines for their electric engines. As trains traverse vast distances, these towering structures have an extensive role in the integrity of the train systems and ensure a reliable and sustainable power source along their tracks. As thousands of catenary poles have been installed along the tracks, precise localization of these poles along the way is crucial for railway infrastructure monitoring. It plays an essential role in inferring the exact location of the inspection train and calculating immediately the accurate position1 of any potential faults for proactive maintenance.
Various data sources could be involved and integrated into the catenary pole detection process. This depends on the types of sensors used for rail inspection. One of the most common data sources is Radar systems. It operates through the principle of emitting radio frequency signals and analyzing the reflection or echo that returns after hitting objects in their path. Along the same pattern, radio signals could be replaced by laser beams where the phase shift of the returned signal differs from the emitted one and hence provides an efficient means for detecting the distance to the intercepting object. On another front, LiDAR (Light Detection and Ranging) sensors capture detailed 3D information about the surrounding environment on the railway tracks. LiDAR data could provide a good resource for mapping and identifying catenary poles with precision. On the other hand, high-resolution images provide visual data that can be processed through image processing algorithms and Computer Vision (CV) models to identify and analyze catenary poles. The added value of processing ground-level image streams is providing a visual perspective for the detection process. Many other data sources could be employed for catenary pole detection, for example, but not limited to, satellite imagery, aerial photography, electrical monitoring of in/out signals, vibration sensors, Infrared images, etc.
Different data sources may entail different kinds of processing and may necessitate data combination and integration. This concept is well known in the data science and Artificial Intelligence (AI) literature as model fusion or ensemble modeling where multiple heterogeneous data sources and models are collaboratively involved for more consistent, robust, and accurate predictive models. The goal of model fusion is to leverage the strengths of different diverse models and compensate for their weaknesses and limitations. In this context, RAILwAI pays close attention to these revolutionary technologies in railway inspection that could be a game-changer thanks to the enormous existing data sources that could be used to monitor the same phenomena. We present here one of our recent models that is designed to assimilate model fusion for catenary pole detection.
Model Fusion
For this setup, we assume we want to recognize the state of an object (e.g. its position) from several measurements. Those measures can come from different data sources/sensors each reflecting part of the information required to estimate its state.
We can consider each measurement for a given object as an instance/view and consider the object as a multiple instance item where each of its views can be complementary (e.g., in case of multimodality) or redundant information about its state (e.g., different candidate measure of the same quantity). In this case, it is interesting to combine those to have a robust and unbiased estimate of the state of the object.
A common strategy to assess this is to consider an assembly of several (trainable or deterministic) modules to extract the relevant information from each instance of the object. Then, we perform a fusion of the extracted information to produce the final estimate of its state.
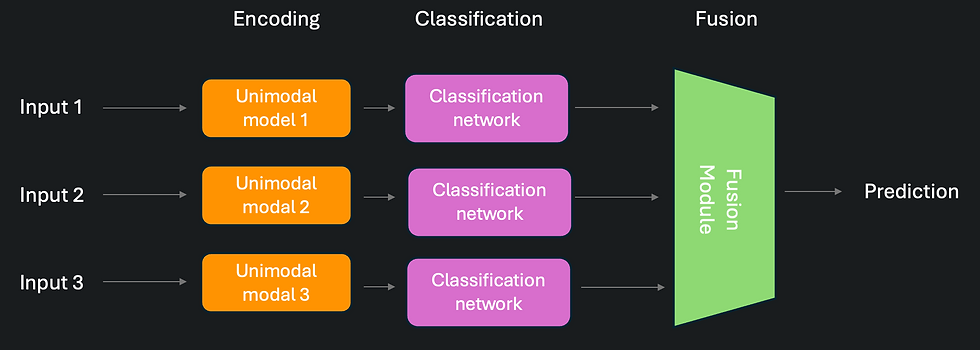

Figure 1: Representation of a late fusion pipeline (a) and an early fusion pipeline (b).
There are two main model fusion paradigms - late and early fusion.
Late fusion scheme, as shown in Figure 1.a, is the most straightforward as it often simply consists of training each model of the assembly to predict the estimate of the state of the object and then to combine those predictions to have a robust estimate. For example, if the targeted state to estimate is the position of a given object from different sources, we can simply return the average predicted position across this committee of models. This will impact positively the confidence of the estimation.
For early fusion scheme, as shown in Figure 1.b, we assume an assembly of encoding models, each trained separately from the other on its corresponding data source, to produce feature vectors for the corresponding instance related to the object. A general representation vector is produced from all the feature vectors through a fusion module and a final classifier model is trained on top of those general vectors’ representations of all instances.
The advantage of the early fusion paradigm is it provides a way to somehow learn how we should combine the instances and is well suited in case of complementarity between the information contained in the different views of the object. On the contrary, late fusion schemes are more suited to provide robust estimates (with reduced prediction uncertainty) from redundant information contained in the different instances. That information can come from different modalities, but each intrinsically contains the same information about the state of the object.
Case study: Catenary Poles Detection
We will present one of our recent modules at RAILwAI for catenary pole detection that exploits the data coming from two different sensory sources and employs model fusion for better reliability of the prediction. The first data source is the ground-level images from the heading on-board cameras that capture images continuously. We utilize two different views from two different cameras. In this case, we employ CV-based models. The other source uses the numerical time series data streams coming from laser-based sensors that jointly measure the height of the catenary wires and the misalignment offset of the rails. Hence, we apply Digital Signal Processing (DSP) algorithms and models. Let’s have a closer look at both types of models!
Model-I (CV Models)
For the first model, we used a combination of state-of-the-art semantic segmentation based on deep learning and a classification module used on top of the geometric features extracted in the previous stage. Deep learning-based segmentation models now provide outstanding results for generic visual object localization within a frame. They usually allow very good zero-shot learning results, i.e., there is a very limited need for retraining them on the task at hand.


Figure 2 : Some examples of semantic segmentation applied on top camera viewpoint.
For this example of pole detections, such a model can however miss some of them due to varying conditions (e.g., global lightning, weather conditions, etc.) that were not seen during re-training of the model. As such models require a tremendous quantity of data to be trained (even for fine-tuning), we decided to refine the detection accuracy by training a classification model on top of it. The segmentation model is then used as a generic lower-level geometric features extractor on top of which a simple classification model can be trained. Putting such prior knowledge in the training process allows us to dramatically reduce the number of training examples required to achieve good performance while saving computational resources (more efficient, sustainable, and ecological).

Figure 3 : A result of the full classification pipeline to detect the catenary pole’s location. We see here that we still have some mistakes due to ambiguity between detecting vertical wires and catenary poles.

Figure 4 : A result of the full classification pipeline from a different camera viewpoint for the same rail segment. Here we see that this viewpoint does not contain the same ambiguous information that the previous one from Figure 3.
In Figures 3 and 4, we can show some results of this vision pipeline applied on different cameras of the train which will allow us to provide a better estimate of their precise location. For instance, bad detections of poles for vertical wires will be eliminated while fusing the different detections coming from different viewpoints. In the next section, we describe another estimator from a different modality of measurement that would allow us to be even more robust if one of the model estimates is inaccurate or simply misses the pole.
Model-II (DSP Model)
For the second model and to identify the location of the poles, we used the the highest points of the hight signal of the highest the catenary wire along with the corresponding displacement offset signals for identifying the location of the poles. To this end, we apply digital signal processing algorithms and features extracted from these series after passing it to extensive preprocessing steps: to smooth the signals, remove the outliers, and extract proper hyperparameters to the next stages. For feature extraction, we used a comprehensive set of features that represent signals in both time and frequency domains. We split the signals into segments and hence into small frames not only to extract proper local features but for better utilization of the computational resources as well. Figure 5 shows one of these segments highlighting the resulting output of the model which represents the suggested location of the catenary poles.

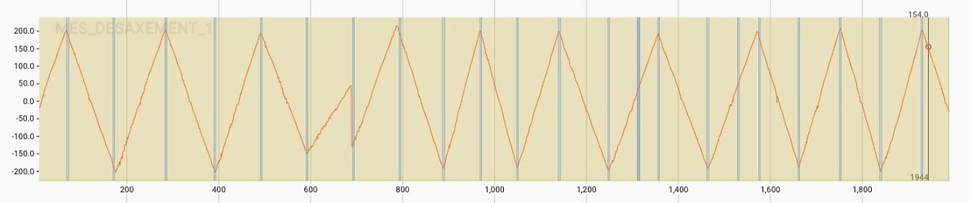
Figure 5 : Catenary pole locations mapped to the height signal (a) and the displacement offset signal (b)
Fusing Both Models
We apply different schemas for model fusion within the main paradigm of late and early strategies. Relying on the ensembles of these models helps to tackle the main challenges for catenary pole detection including varying environmental changes (adverse weather conditions), complex terrain (curves, slopes, and densely vegetated areas), and the dynamic nature of railway operations (varying speed). We noticed a varying performance of the individual models concerning these factors and conditions which creates more diverse and powerful model ensembles. Nonetheless, data integration and model fusion introduce other challenges. Most notably, the synchronization between diverse data sources, and the effective utilization and optimization of the computational resources. At RAILwAI, we propose different solutions for all these challenges and adaptive fusion of the predictive models to guarantee more sustainable and continuous operations.
Industry Implications
In modern machine learning models, the learning process itself is a never-ending course. Predictive models could be well designed to grasp other sources of information to guarantee the reliable evolution of their performance. One of the most significant sources is human experts. Therefore, integrating human-in-the-loop through Interactive Machine Learning (IML) is deemed to be the cutting-edge paradigm for cooperating human and machine intelligence to benefit each other in a mutually rewarding way.

Figure 6 : Interactive Machine Learning iterations.
From experts’ point of view, close interactions with AI models could provide a good way to observe the performance of these models and visualize not only their final predictions but the intermediate outputs of their subsystems compounding them as well. As ML is mostly criticized for its difficulty in interpretation, interactive machine learning could reveal deep insights into these models to provide more explainable and interpretable models. On the other hand, incorporating experts’ feedback by the ML models as a part of the learning process improves the generalization capabilities of these models to come up with more robust and reliable versions.
With the recent advancement in computer vision models, RAILwAI intended to involve visual predictive modules in the ensemble of the fusion process. This will permit and facilitate human experts’ interaction with the model. Since for humans, visual tasks are usually easier than other tasks (predictions from signals), this will require less expertise to close the feedback loop with the model. According to the European Artificial Intelligence Act (AI-ACT) 2, machine learning and AI models are highly advised to adhere to certain conditions for safe deployment in critical applications and industries. This requires considering the traceability, transparency, human oversight, accuracy, and robustness of AI-based systems. The AI-Act pays close attention to Human-Centric AI (HCAI) and the creation of human feedback loops to address possibly biased outputs (Art.15 No.3). Therefore, it is highly recommended to consider the importance of feedback in maintaining and improving the safety level of AI applications deployed in the railway sector. The aim is to enhance the interpretability and explainability of AI models which are often viewed as black boxes. However, this leads to many open questions of whether such models can be reproduced, and their evolution tracked.
If you're interested to find out more about our innovative solutions and services, please reach out to RAILwAI to explore a broad set of possibilities for putting your data on the smart track.


Comments